腾讯大数据将开源计算平台 Angel,机器之心专访开发团队


机器之心原创随着近年来深度学习技术的发展,各种机器学习平台也纷纷涌现或从专用走向了开源。到现在,一家科技巨头没有一个主导的机器学习平台都不好意思跟人打招呼。比如谷歌有TensorFlow、微软有CNT......
机器之心原创
随着近年来深度学习技术的发展,各种机器学习平台也纷纷涌现或从专用走向了开源。到现在,一家科技巨头没有一个主导的机器学习平台都不好意思跟人打招呼。比如谷歌有TensorFlow、微软有CNTK、Facebook是Torch的坚定支持者、IBM强推Spark、百度开源了PaddlePaddle、亚马逊也在前段时间高调宣布了对MXNet的支持。
现在,腾讯也加入了这一浪潮。在12月18日于深圳举办的腾讯大数据技术峰会暨KDDChina技术峰会上,腾讯大数据宣布推出了面向机器学习的「第三代高性能计算平台」——Angel,并表示将于2017年一季度开放其源代码。
腾讯副总裁姚星在大会发言中说道:「人工智能的发展在过去60年中几经沉浮,今年终于发出了璀璨光芒,很大的原因就是跟云计算和大数据有关,这是一种演进发展的必然结果。如何处理好大数据,如何在有限的计算资源上对这些大数据进行深入挖掘和分析,这是未来整个产业发展和升级的一个大课题。我相信大数据将成为这次产业升级的基础,核心算法将成为这次产业升级的灵魂。」
在这次会议上,腾讯数据平台部总经理、首席数据专家蒋杰详细分享了腾讯大数据的发展之路以及Angel系统构建的生态圈层。据介绍,Angel是腾讯大数据部门发布的第三代计算平台,使用Java和Scala语言开发的面向机器学习的高性能分布式计算框架,由腾讯大数据与香港科技大学、北京大学联合研发。它采用参数服务器架构,解决了上一代框架的扩展性问题,支持数据并行及模型并行的计算模式,能支持十亿级别维度的模型训练。
近期,机器之心对腾讯数据平台部总经理、首席数据专家蒋杰进行了一次专访,请他详细谈了谈Angel的开发和开放背后的故事。(注:后文还附有蒋杰在本次会议上的演讲)
一、Angel特点与优势
为什么会选择在这个时间点开源Angel?你怎么看待目前市面上开源的机器学习平台?相比于其他平台,Angel的优势是什么?
并不是我们刻意选择一个时间,而是水到渠成的过程。Angel已在腾讯内部使用了一段时间,系统稳定性和性能经过了腾讯业务的检验,系统达到了一定成熟度,因此现在到了开放给所有用户的时候,希望能激发更多开放创意,让这个好平台逐步转化成有价值的生态系统。
目前的一些主要机器学习平台:
1)Spark(MLlib):采用MapReduce的计算模型进行分布式机器学习的计算,通用性较好,但不是很适应大规模的模型。
2)Petuum:Petuum验证了SSP的可行性,这是它带来的最大的贡献,功能方面也比较完备,不过在一定程度来说,更像是一个实验室的产品,离工业界的应用还有一段距离。
3)TensorFlow:Google开源的机器学习系统,用来替代DistBelief。提供了Tensor流编程模型,主要的优势在于为深度学习提供了通用的算子和GPU并行计算,目前TensorFlow开源的版本比较适用于单机多卡的环境,在多机多卡上性能有瓶颈。
Angel的哪一项特性最能吸引开发者?
更高性能、更易用,并且在腾讯内部经历过十亿级别的大规模应用的考验,适合工业界使用。
根据这个数据(下图),Angel的迭代时间显著优于Spark,尤其是在模型较大的时候差距更是明显,达到这种效果的主要技术进步是什么?请通俗地解释一下。

Angel的模型,是分布式存放于多台高性能ParameterServer之上的,并且对模型的pullpush都做了专门的优化,对于大部分的机器学习算法,在模型越大的情况下,比起Spark的单点模型广播方式,性能自然越好。
请对比一下Angel与Spark、Petuum、GraphLab(Turi底层技术,被Apple收购)等平台。
Spark的通用性很好,但架构上不适应大规模参数交换,因此我们才研发了Angel。Petuum验证了SSP的可行性,这是它带来的最大的贡献,功能方面也比较完备,不过在一定程度来说,更像是一个实验室的产品,离工业界的应用还有一段距离。GraphLab图方面很强,但是很多机器学习算法不适合抽象为图模型,因此通用性方面不够好,另外,容错性一般。
至于Angel,我们主要融合了Spark和Petuum的优点,避免它们的一些短板,我们在性能、易用性、可靠性方面做了很大的加强。
为什么考虑用JavaScala来开发这个系统?而不是通常的C/C++?
主要是一个延续性的考虑,腾讯大数据平台起源于Hadoop和Spark,都是基于Java,考虑到用户的习惯,所以使用相同的语言,对于他们来说接受成本更低。另外,Scala在接口更加的丰富和有表现力,也会对用户更加友好。
另外是部署和升级的简单性,之前公司的分布式平台用的是Java架构为主,在这些机器上进行Angel运行资源的申请,都是透明的,迁移代价很低。
目前我们了解到Angel在模型方面已经支持了LatentDirichletAllocation(LDA)、MatrixFactorization(MF)、LogisticRegression(LR)、SupportVectorMachine(SVM),而这些模型都离不开矩阵运算。可否谈谈Angel在矩阵运算上做了哪些优化?
目前提供Vector,Matrix库,支持各种表达形式(稀疏或稠密)和常见存储格式(CSR,COO等),支持常用数据类型和线性代数计算。
你们在参数服务器上做了哪些优化?和DistBeilef相比,又有哪些不同?
Angel是基于参数服务器的一个架构,与其他平台相比,我们做了很多优化。首先,我们能支持BSP、SSP、ASP三种不同计算和参数更新模式,其次,我们支持模型并行,参数模型可以比较灵活进行切分。第三,我们有个服务补偿的机制,参数服务器优先服务较慢的节点,根据我们的测试结果,当模型较大时,能明显降低等待时间,任务总体耗时下降5%~15%。最后,我们在参数更新的性能方面,做了很多优化,比如对稀疏矩阵的0参数以及已收敛参数进行过滤,我们根据参数的不同数值类型进行不同算法的压缩,最大限度减少网络负载,我们还优化了参与获取与计算的顺序,边获取参数变计算,这样就能节省20-40%的计算时间。
关于DistBeilef,我们阅读过跟它相关的一些论文和资料,原理上有一定类似,但因为它没有开源,因此没有办法进行具体细节上的比较,但目前谷歌也用TensorFlow来替换它了。
能够支持数亿甚至数十亿的特征维度需要对系统基础架构和算法本身进行多方面的改进,特别是在算法方面,需要对每个算法进行特别的优化。Angel在基础架构(infrastructure)和算法方面都做了哪些主要优化?
正如刚才所说,Angel是基于分布式参数服务器的一个架构,它解决了Spark上做参数更新的网络及计算的瓶颈,同时,我们在参数更新、网络调度、降低网络负载等等做了很多架构上面的优化,可以支持数据并行和模型并行,这样才能支持更大的模型。
在算法方面,其实算法种类繁多,每种都有自己特定的优化方法,但有框架上,会有一些通用的优化方法:
对传输的算法模型进行低精度压缩,用较少的字节传输浮点数,减少网络流量,加快系统速度;
每个计算节点建立索引,只向PS获取本节点需要的模型子集;
过滤掉对模型影响较小的更新值,降低网络传输数据量等。
除了这些通用的方式,Angel针对每种算法也做了大量有针对性的优化,例如GBDT、LDA等。
GBDT:在PS端提供自定义的Pull函数,在server端完成树节点的分裂,避免将整个梯度直方图发送到计算节点,极大减少网络流量。计算节点向PS端Push本地的梯度直方图时,使用低精度压缩。
LDA:Angel实现了各种LDA的sampler,可以根据具体应用场景选取最合适的sampler;充分利用了数据稀疏的特点和非均匀分布的特点,提供高效的压缩方式,降低传输数据量;根据数据的分布情况来进行矩阵的划分策略,从而达到ps的负载均衡;对不同的词做了细粒度的调度,可以根据词-话题矩阵和文档-话题矩阵的大小来选择是在worker上做计算还是在server上做计算,从而减少网络开销。
Angel和Spark一样属于in-memory计算吗in-memory计算的一个难点在于资源配置和内存管理。在腾讯内部,Angel-as-a-service是如何做到能够处理不同规模、频率、算法、时间需求的工作量的?
是的,Angel也属于in-memory计算,但是,Angel占用的内存会比Spark小很多,因为Angel主要针对机器学习,专门进行了优化。另外,Angel并不是一个常驻服务,每个计算任务独立,它的生命周期和计算任务一致,不长期占用。我们可以通过参数来设置Angel占用的资源量,也可以通过训练数据量和模型计算一个默认的资源占用量。
二、Angel与深度学习
Angel对深度学习和强化学习的支持怎么样?支持GPU吗?
Angel支持基于GPU的深度学习,它支持DL4J,另外,目前Angel还能支持如Caffe、Torch和TensorFlow等业界主流的机器学习框架,提供计算加速。两年前我们就开始在效果广告领域尝试使用深度学习,深度学习+在线学习在我们的效果广告取得很好的效果。我们也在广告领域开始强化学习的应用实验,并探索深度学习+强化学习的融合。
在TensorFlow、MXNet等其它架构上已经实现的模型迁移到Angel上的难度有多大?
我们在整体架构层面有兼容不同计算框架的设计考虑,同时我们建设了很多相对应配套的工具来降低迁移成本,因此,整体迁移难度很低。
三、安全和隐私
随着信息安全和数据保密需求的日益增加,腾讯的基于云的大数据分析服务面临哪些信息安全和数据隐私的要求?这些要求如何影响了像Angel一样的系统的设计和实现?
四、背景与展望
在SortBenchmark大赛中腾讯团队获得了GraySort和MinuteSort两项的冠军,速度大幅提升背后应用的技术是怎样的?为何能获得如此大的速度提升?
比赛冠军,可以说是腾讯大数据平台的厚积薄发,我们的平台发展了7年,历经了三代的演进,经历了离线计算、实时计算、机器学习的三大阶段的发展,我们的平台每天都在经受着腾讯数以万亿计的业务量的考验,腾讯的业务量大并行业务类型复杂,迫使我们在高性能计算及资源调度方面必须适应业务的要求,必须灵活、性能高,并要有很好的灵活性。正式有了这些积累,才让我们在比去年更低的成本的条件下取得比去年提升几倍的成绩。
腾讯内部已经用到了哪些基于Angel的产品?在推广中有哪些问题吗?
开发这个框架投入了多少资源?开发团队有多少人?
Angel项目在2014年开始准备,2015年初正式启动,刚启动只有4个人,后来逐步壮大。项目跟北京大学和香港科技大学合作,一共有6个博士生加入到我们的开发团队。目前在系统、算法、配套生态等方面开发的人员,测试和运维,以及产品策划及运维,团队超过30人。
Angel已经支持了SGD、ADMM优化算法,后续还将支持哪些算法?
主要看用户需求,应用有需要的,我们就会支持。
能谈一下Angel此次开源的原因和意义吗?Angel后续的短期计划和长期计划是什么?
腾讯大数据平台来自于开源社区、受益于开源社区,所以我们自然而然地希望回馈社区。开源,让开放者和开发者都能受益,创造一个共建共赢的生态圈。在这里,开发者能节约学习和操作的时间,提升开发效率,去花时间想更好的创意,而开放者能受益于社区的力量,更快完善项目,构建一个更好的生态圈。我们一直都在回馈社区,开放了很多源代码,培养了几个项目的committer,这种开放的脚步不会停止。
开源只是个开头,后续我们会努力做好社区建设,我们会投入比较多的资源来响应社区的需求,我们会为Angel建设更多更好的配套生态来支持更多的业务场景。
目前国内外几大科技巨头都在主推一个开源平台,腾讯此次开源后,如果看待这种竞争格局,以及腾讯在这方面的竞争优势?
竞争一直都会存在,竞争促使进步,会让整个行业发展更快,所有从业人员和用户都是好事。至于各企业的平台,每家都有自己的优势,也有不足,开源能促使短板被优化。让竞争来的更猛烈些吧。
为什么命名Angel?开发中有什么有趣的故事吗?
我们开发的初衷是一个可以计算更大模型,速度快到飞起来,像插上翅膀一样的平台,也希望它对用户足够友好,门槛低,易用性高,会是一个友好善良的平台形象。另外,这个项目对我们几个开发人员来说非常重要,心里很宝贝这个项目,所以自然而然想到了Angel。
以下是腾讯数据平台部总经理、首席数据专家蒋杰在本次会议上的演讲整理:
很多人已经知道腾讯获得了今年的SortBenchmark的排序的4项冠军,很多朋友来问我:腾讯是怎么做到的,背后支撑的究竟是什么样的技术?
今天,我借这个机会,跟大伙来讲讲背后的一些故事。
相信很多人看过我们在很多城市机场投放的这个广告,这个广告里面画的是一个赛跑的选手。排序比赛就跟奥运会的百米赛跑一样,都要很快。但我想说的是:其实我们更像一个长跑选手,我们在跑马拉松。这场马拉松,我们跑了7年。
回顾过去几年的比赛成绩,几年前冠军都是被美国企业垄断的,最近三年则是BAT拿了冠军。应该说,这几年,国内互联网的发展速度不比美国慢,与此同时,以BAT为代表的国内互联网企业的计算能力也不落后于美国。
过去几年,获得冠军的团队用的基本上都是Hadoop和Spark。其实腾讯的大数据平台,也是始于Hadoop。
我们之所以能获得四项的冠军,是我们经历了几年的打磨,追求极致,我们希望最大限度地压榨机器的性能。
首先,从成本的角度,只有把硬件压榨到极致,成本才会低。我们采用的是OpenPower架构的机器,按节点数计算,我们规模只有去年冠军的六分之一。按照今年的硬件价格,我们总TCO成本远低于去年的冠军。
在调度层面,我们对调度算法做了深度优化,使得每台机器的CPU、内存、网络、磁盘IO等每个环节都能发挥到极致。本次比赛的其中两项为MinuteSort,比拼的就是一分钟内的排序数据量。在这里,时间调度的效率就变得非常重要,而在这两项比赛上我们比去年提升了5倍——是提升幅度最高的;这也从另一个方面说明了我们在调度效率上的领先性。总结为一句话就是:最大限度地压榨了硬件的性能,才让我们取得了这个成绩。
目前我们用于比赛的这个集群,已经在我们的现网中用起来了,在高性能计算、图计算、深度学习等领域支撑着腾讯的现网应用。
回顾我们走过的7年,我们是2009年1月开始基于Hadoop来开发我们的大数据平台,七年的征程,我们历经了3代平台的发展。
2009-2011年是我们的第一代平台。我们的第一代平台只支持批量计算的场景,主要就是报表。在这个过程中我们重点发展了平台的可扩展性。我们不断增大集群的规模——从09年的几十台发展到了现在总规模接近3万台。总结起来:第一代就是「规模化」。
第二代用三个字总结就是「实时化」。这是2012年到2014年,主要支持在线分析和实时计算的场景,表、实时查询、实时监控等。
第三代是去年到现在,主要是建设机器学习平台来支持腾讯各业务数据挖掘的需求。这是从数据分析到数据挖掘的转变,三个字总结就是「智能化」。、
第一代是离线计算的架构,是基于Hadoop开发的,我们起名叫TDW——腾讯分布式数据仓库(TencentdistributedDataWarehouse)。
社区的Hadoop迭代慢,单一集群规模小,稳定性和易用性都很差,不能达到腾讯的要求,因此我们按腾讯的业务运营标准,做了深度定制开发,我们着重发展集群的规模,解决Master单点瓶颈不能扩展的问题,我们优化了调度策略来提高Job的并发性,也加强了HA容灾建设;还有很关键的一点的是,我们丰富了Hadoop的周边生态,建设了配套的工具和产品来降低用户的使用门槛。语法上,我们兼容Oracle的语法,方便腾讯各产品部门做程序的迁移。Hadoop大数据的性能很强,但是小数据分析的效率很差,我们就集成了PostgreSQL来提升小数据的分析性能,从而打通Hadoop和PG的访问界限。
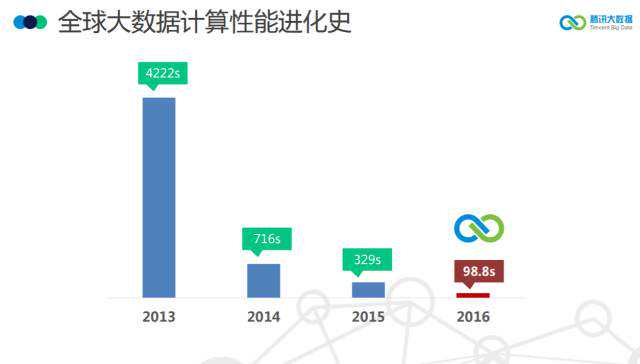
就这样,我们从最开始的几十台、到几百台、到几千台。几年以后,在2013年单一集群达到了4400台,2014年单一集群突破了8800台,处于业界领先的水平。目前我们的总规模接近3万台。
TDW的建成解决了我们内部三大业务痛点:
第一,它使我们具备了T/P级的数据处理能力,几十亿、百亿级的数据量,基本上30分钟就能算出来。
第二,它的成本很低,我们可以使用很普通的PCServer,就能达到以前小型机一样的效果;
第三,容灾方面,原来只要有机器宕机,业务的数据肯定就有影响,各种报表、数据查询都出不来。现在TDW的机器宕机,业务完全无感知,系统会自动做切换、数据备份等等的事情。
正是解决了业务的这些痛点,业务部门都愿意把计算迁移到TDW。到2012年底,我们把所有原来在Oracle和MySQL上跑的报表都切换到TDW。
TDW的建成,让我们具备了融合所有产品平台的数据的能力。
以前的各产品的数据都是分散在各自的数据库里面的,是一个个数据孤岛,现在,我们以用户为中心,建成了十亿用户量级、每个用户万维特征的用户画像体系。
以前的用户画像,只有十几个维度——主要就是用户的一些基础属性,比如年龄、性别、地域等。以前构建一次要耗费很多天,数据都是按月更新,有了TDW,我们每天更新一次。
这个用户画像已经应用在腾讯所有跟精准推荐相关的产品里面。
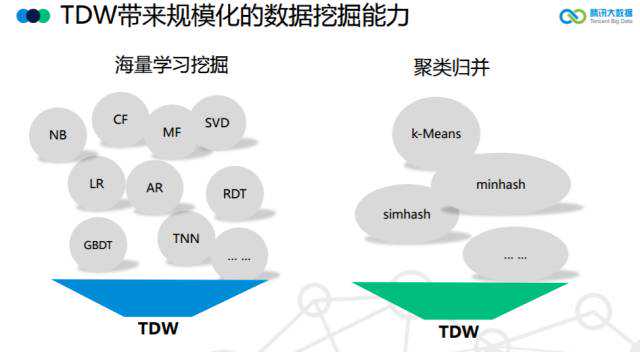
推荐相信大家现在都耳熟能详,但是放在6年前,这还是一个刚刚新兴起的应用;TDW为我们提供了一个快速切入快速支撑的能力。通过MapReduce的编程范式,基于TDW的平台,我们可以专注于各种推荐算法逻辑本身的实现,比如大家常见的CF、MF、LR这些算法、以及各种hash聚类算法;这个时候的推荐技术,面对海量的用户群体访问,更多还是基于一种实时查询的服务方式。
第一代平台解决了量大的痛点,但是在速度方面还有问题——数据是离线的,任务计算是离线的,实时性差。所以,我们建设了第二代大数据平台。
在第一代基础上,集成了Hadoop的第二代——Spark,同时,还融合了Storm流式计算的框架。这一代平台的集成,让我们的计算速度从原来的小时,发展到分钟,直至秒级。
数据采集方面,我们构建了TDBank,让原来通过接口机传文件的方式,T+1的粒度,变成了毫秒级的实时采集。在这个采集平台里面,我们自研的消息中间件每天采集的消息条数超过6.5万亿,可以说是世界上消息量最大的消息中间件。同时,我们还有高可靠版本的消息中间件,能支持像金融、计费等高一致性的需求,保证消息不丢。
在资源调度层面,我们基于Yarn,发展了我们的Gaia调度平台,Yarn只支持CPU和内存的维度,而我们的Gaia还支持网络以及磁盘IO的维度,Yarn只支撑离线计算,Gaia能支持在线的场景,另外,我们还支持Docker,我们平台现在每天有1.5亿container。
第二代的平台,实时性和体量方面都能满足绝大多数业务需求。但随着我们的数据量越来越大,我们的瓶颈很快也出现了。
我们在Spark上做数据训练的时候,每一轮的迭代,在更新数据的时候,都会遇到网络方面的瓶颈——因为更新数据的地方是一个单点,如果数据的维度很大,这套框架就无法支撑。在我们的实际应用中,千万级的维度都可以运行得不错,但是上了亿级,性能就非常低了,甚至跑不出来。
所以,我们必须要建设一个能支持超大规模数据集的一套系统,能满足billion(十亿)级别的维度的数据训练;而且,这个系统必须能满足我们现网应用的工业级需求。它能解决bigdata和bigmodel的需求,它既要能做数据并行,也要能做模型并行。
在这个问题上,存在两种解决的思路:一个是基于第二代平台的基础上做演进,解决大规模参数交换的问题。另外一个,就是新建设一个高性能的计算框架。
我们看了当时业内比较流行的几个产品:GraphLab(主要做图模型,容错差);Google的Distbelief(还没开源);还有CMUEricXing的Petuum(当时很火,不过它更多是一个实验室的产品,易用性和稳定性达不到我们的要求)。
看了一圈,我们决定自研,走自研的路。我们前两代都是基于开源的,第三代则开始了自研的历程。其实在第二代,我们已经尝试自研,我们消息中间件——不论是高性能的,还是高可靠的版本——都是我们自研的。它们经历了腾讯亿万流量的考验,这也给了我们在自研方面很大的信心。
因此,第三代整体的计算框架方面,我们也走了自研的道路。第三代的平台,核心是一个叫Angel的高性能计算平台。
我们聚焦在高性能的计算框架方面,同时,也是我们往机器学习、深度学习演进的一个路线。
相比第二代,第三代的计算框架,可以支持10亿级维度的算法训练,由以前的数据并行,到可以支持模型并行。同时,我们第三代的平台,还支持GPU深度学习,支持文本、语音、图像等非结构化的数据。
Angel是基于参数服务器的一个架构,它跑在我们的Gaia平台上面的。它支持BSP、SSP、ASP三种计算模式;支持数据并行以及工业界更看重的模型并行(因为我们主要碰到的还是模型大的问题);另外,在网络上我们有个原创的尝试,我们用了香港科技大学陈凯教授团队做的诸葛弩来做网络调度;ParameterServer优先服务较慢的Worker,当模型较大时,能明显降低等待时间,任务总体耗时下降5%~15%。
Angel提供很丰富的算法,支持LR、SVM、LDA、GBDT等等,并且集成了非常丰富的数学函数库,另外,还提供非常友好的编程界面,能跟Spark、MR对接,你能像用MR、Spark一样编程。
Angel跟其他平台(比如Petuum和Spark等)相比,就我们的测试结果,在同等量级下,Angel的性能要优于其他平台。比如我们用Netflix的数据跑的SGD算法,大家看一下这个图的对比:
同时,Angel更适合超大规模的数据训练。目前Angel支持了很多腾讯内部的现网业务。这里举两个例子,比如,在构建用户画像方面,以前都是基于Hadoop和Spark来做,跑一次模型要1天甚至几天,话题只有1k;而在Angel上,200多亿文档、几百万个词、3000亿的token,1个小时就跑完了。以前Spark能跑的,现在Angel快几十倍;以前Spark跑不了的,Angel也能轻松跑出来。
Angel不仅仅是一个只做并行计算的平台,它更是一个生态,我们围绕Angel,建立了一个小生态圈,它支持Spark之上的MLLib,支持上亿的维度的训练;我们也支持更复杂的图计算模型;同时支持Caffe、TensorFlow、Torch等深度学习框架,实现这些框架的多机多卡的应用场景。
各位,临近尾声了,我想总结一下腾讯大数据平台发展的三个阶段:我们从离线计算起步,经过实时计算阶段,进入了机器学习的时代。我们从跟随开源,发展到自研,我们的发展历经了规模化、实时化,以及智能化的变迁。
最后,我要借这个机会跟大家公布一个消息,那就是:我们的大数据平台将全面开源。
我们会在明年上半年把Angel以及Angel周边的系统进行开源。我们平台源自开源,我们的发展离不开开源,所以我们会以最大的力度拥抱开源。其实在开源的道路上,我们一直都在参与:我们第一代平台的核心TDW-Hive在2014年就开源了;我们还在很多社区项目贡献了很多核心代码,培养了好几个committer。而未来,我们的开源力度只会越来越大。
谢谢大家。
本文链接:https://pxjs.bugohfangsheng.com/320585892490.html